

Auteurs:
Jasper Loos ● jloos@nekst-it.com
John Kronenberg ● johnkronenberg@qacompany.nl
Redactie: Paul Beving
Ondergetekenden hebben los van elkaar meerdere ETL projecten gedaan. Het testen van ETL vraagt een andere benadering dan bijvoorbeeld het testen van een webpagina, maar in deze ogenschijnlijk zeer verschillende testobjecten heeft het kwaliteitsattribuut ‘Functionele geschiktheid’ uit de ISO-25010 een belangrijke plek om dekking op te bereiken. Onze belangrijkste leerervaring is dat ook al is ETL een ‘big-dataset’ oplossing, je het bij voorkeur niet als een ‘big-dataset’ oplossing moet willen testen! Bij veel projecten zien we dat testers de focus leggen op het via gegevenskwaliteit aantonen van ‘Functionele geschiktheid’. Wij denken dat de focus bij Datawarehouse-projecten moet liggen op het bewijzen van de functionaliteit van de oplossing met de kleinst mogelijke hoeveelheid testdata. In dit artikel noemen we dat een ‘small-dataset’. Met het automatiseren van de voorgaande ‘small-dataset’ testen is de ETL oplossing goed functioneel af te dekken. Als de functionaliteit van het Datawarehouse is bewezen, kan de ‘big-dataset’ testen de datakwaliteit van het Datawarehouse aantonen.
Wat is ETL?
ETL (Extract Transform Load) is het proces dat data-gestuurde organisaties gebruiken voor het verzamelen en samenvoegen van data uit meerdere bronnen voor het ondersteunen van detectie, rapportage, analyses en besluitvorming. Deze ETL leidt in de meeste gevallen tot een gevulde Datawarehouse. Een Datawarehouse is een type databeheersysteem dat is ontworpen om business intelligence-activiteiten (BI), met name analytics, mogelijk te maken en te ondersteunen. Op de data in de Datawarehouse wordt dus over het algemeen BI-rapportages en dashboards gebouwd.
Waarom is ETL testen zo belangrijk?
Het succes van veel organisaties is afhankelijk van informatie die uit data wordt gehaald. Incorrecte of onvolledige data kan leiden tot verkeerde beslissingen, waardoor het testen van de ETL pipelines die de data verwerken essentieel is. Een ETL pipeline bestaat vaak uit meerdere processen en integraties die data extraheren, laden en transformeren. Dat zijn de integratiepunten waar testen van waarde is.
Waarom moet je ETL oplossingen niet (alleen) testen met een ‘big-dataset’?
Het is verleidelijk om bij het testen van ETL oplossingen alleen te kijken naar hoe de data er aan het eind van de pipeline uitziet. Dit is een vorm van validatie die helpt bij het in kaart brengen van de datakwaliteit en eventuele problemen in de brondata. Als hier echter een issue wordt gevonden, is het lastig om te achterhalen waar in de pipeline het (functioneel) precies misging. Bij ETL testen is het van belang dat je de afzonderlijke functionaliteiten binnen een pipeline in kaart brengt en hier gerichte testen op uitvoert. Deze testen kun je het beste uitvoeren met een ‘small-dataset’. Zo reduceer je de complexiteit van het testen, verlaag je de doorlooptijd en identificeer je bugs in de pipeline vroegtijdig.
Welke testaanpak is wel geschikt?
Om een ETL oplossing te testen is het dus verstandig om in eerste instantie te focussen op de requirements (lees: transformatieregels) waar het DWH aan moet voldoen en niet op de gegevenskwaliteit in het Datawarehouse. In de praktijk is die focus op functionaliteit het beste in het team te krijgen door de testen op te zetten middels Behavior Driven Development (BDD). Op basis van de Three Amigo Sessies kan dan de transformatieregels voor iedereen inzichtelijk worden gemaakt.
Zogezegd is het verstandig om de testgevallen die je hebt gedefinieerd te testen met zo min mogelijk testdata. Voor ‘small-datasets’ testen is het handig om een dedicated testomgeving te hebben, zodat je de testgevallen volgens het volgende proces kunt uitvoeren.
- Gooi de databases in je datawarehouse leeg
- Voer de small-dataset voor het testgeval op in Staging
- Draai de ETL workflows / ETL pipelinescript
- Controleer de resultaten van het testgeval
- Rapporteer de resultaten, en merk fouten ten opzichte van verwacht in je rapportage op
- (Start volgende testgeval door stappen 1 tot en met 5 te herhalen)
Om bovenstaand proces goed te laten werken is het belangrijk dat je per uitgevoerd testgeval kunt zien wat het resultaat van dat specifieke testgeval is geweest. Je wilt exact weten welk testgeval gefaald is. Als je de testgevallen batchgewijs uitvoert, is het stukken lastiger om exact te pinpointen welk stukje functionaliteit een bug bevat.
Om de ETL testgevallen met weinig inspanning te kunnen herhalen is het verstandig om regressie-testautomatisering op te zetten. Als voor BDD wordt gekozen zijn prima open-source tools om die testautomatisering neer te zetten Cucumber, Robot Framework met de Gherkin plugin of Pytest.
Hoe hebben wij het gedaan?
Voor een organisatie die gebruikmaakt van een aantal AzureAnalytics producten ziet de ETL pipeline er ongeveer zo uit als het door Microsoft op de website gebruikte voorbeeld:
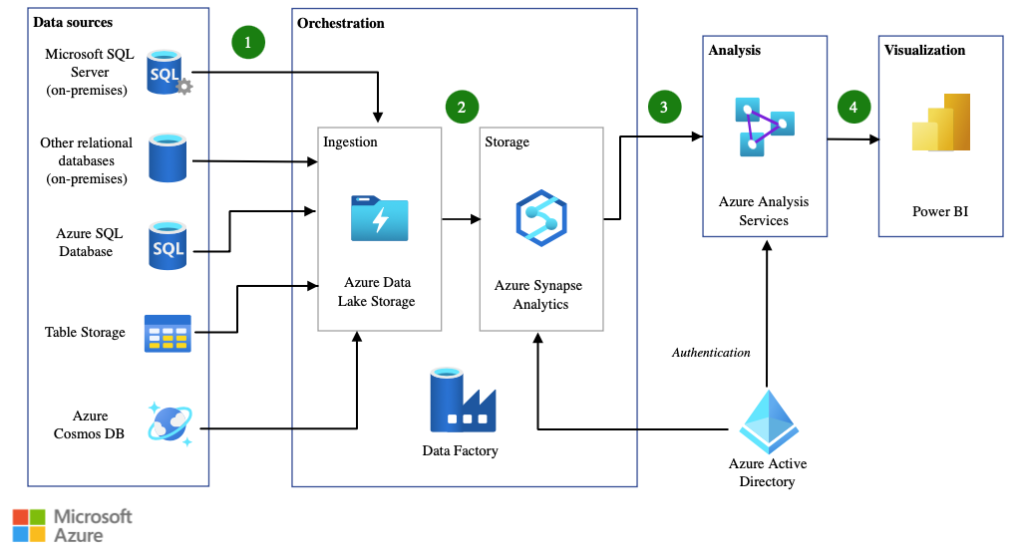
Hiervoor is een testautomation-strategie opgesteld, bestaande uit verschillende testsoorten om de verschillende integratiepunten gericht te testen. Met behulp van Python libraries als Pytest, Pytest BDD, Pyodbc, Pandas en Requests is de organisatie in staat gesteld om het volledige dataplatform geautomatiseerd te testen. De testen draaien in een geïsoleerde testomgeving met kleine sets aan productie-like testdata. Hierdoor is reproduceren en debuggen van bevindingen eenvoudig uit te voeren door ontwikkelaars, data-engineers en testers. De testen zijn geïntegreerd in de CI/CD omgeving in Azure DevOps, waar ze bij elke deployment naar de testomgeving draaien. De validatie van productiedata wordt in een los proces gedaan op een omgeving waar productiedata mag staan, door middel van de tool Great Expectations.
Resultaten van de aanpak?
Het testautomation framework stelt de organisatie in staat om codewijzigingen sneller te testen en naar productie te brengen, met zekerheid over de kwaliteit van de software. Door de complexiteit van ETL pipelines kan het handmatig testen van codewijzigingen dagen duren. Het testautomation framework voert diezelfde testen in minder dan een half uur uit.
Voordelen van de aanpak?
De volgende voordelen worden onderkend:
- Hogere testdekking met kortere doorlooptijd;
- Levende documentatie over business requirements;
- De ontwikkelaar verkrijgt onmiddellijke feedback over de kwaliteit van de software;
- In een programmeertaal waar ontwikkelaars zelf aan kunnen bijdragen;
- Generieke opzet zorgt voor herbruikbaarheid voor andere leveranciers.
Nadelen van de aanpak?
Er zijn ook nadelen van de aanpak te benoemen. De volgende nadelen onderkennen we:
- Er is een specifieke skillset nodig (test, ontwikkel, databases, CI/CD);
- De organisatie moet bereid zijn om een tijdsinvestering te nemen.
Takeaways
Samengevat zijn onze belangrijkste leerervaringen op het gebied van ETL testen:
Probeer functionele dekking te bereiken door ‘Small-Dataset’ testing in te zetten (productie-like data per datastroom en per case).
Teststrategie moet idealiter uit meerdere testsoorten bestaan, die complementair aan elkaar zijn:
- Small Dataset testing (focus op functionaliteit);
- Big Dataset testing (focus op datakwaliteit).
In de meeste gevallen is testautomatisering buiten de ETL tool om en opgezet volgens BDD, de beste keuze.
Omdat je developers wilt betrekken bij testautomatisering, probeer een programmeertaal te kiezen die in het project gebruikt wordt (Python, Java, .NET)