Auteur: Kees Blokland ● kees.blokland@polteq.com

Hoe kies je geschikte testgevallen? Er bestaan allerlei technieken die je helpen die vraag te beantwoorden. Zowat iedere introductiecursus softwaretesten start de techniekenuitleg met ‘equivalence partitioning’, soms vervat in een datacombinatietest of de classification tree methode. Ik gebruik de gratis tool testona regelmatig om met een classification tree de gewenste testdekking ergens van in kaart te brengen. Recentelijk ontwikkelde ik daarbij een handigheidje die ik jullie niet wil onthouden.
Equivalentieklassen
Hoe kan ik vele mogelijke situaties in klassen indelen en met een test per klasse een overzichtelijke testdekking realiseren? Als de aanname waar is dat de software die ik test hetzelfde werkt voor situaties in dezelfde klasse, is die testdekking zelfs al best hoog. Uiteraard een discutabele aanname: in de praktijk blijken klassen weer te bestaan uit verschillende situaties die niet zijn gemodelleerd, waardoor de testideeën die daarbij horen buiten de boot vallen. Maar dat is niet het onderwerp van deze Kijk.
Alleseter
Wat mij bevalt aan de classification tree methode, is dat het een alleseter is. Het maakt niet uit waar je de informatie vandaan haalt, hoe die informatie eruitziet, je kunt het eigenlijk altijd kwijt in een classification tree. Of het nu gaat om verschillende resultaten of over verschillende gegevens als input: het past allemaal in het schema. Als je denkt compleet genoeg te zijn, begin je met testgevallen te ‘trekken’. Dit zijn horizontale strepen met uit ieder blokje een klasse gekozen. Om dit te volgen moet je even naar het plaatje kijken. De bolletjes laten zien of iedere klasse minimaal een keer is meegenomen in een test (wat in het voorbeeld trouwens niet helemaal het geval is). Hierna volgt nog wat administratie om van elk geval de startsituatie te bepalen, de actie en het verwachte resultaat: de basisingrediënten van testgevallen, zoals we dat ook hebben geleerd. Best jammer dat dit niet meteen op overzichtelijke wijze in de classification tree zichtbaar was.
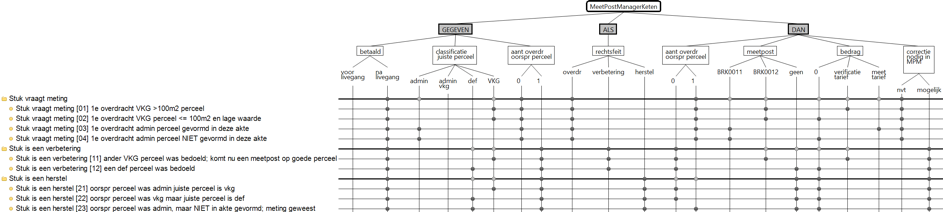
Gherkin
Het mooie is: dat is best makkelijk te realiseren. Als je bij het bepalen van de classification tree de classificaties meteen indeelt in
– uitgangssituaties
– testacties
– resultaten
en je hangt de uitgangssituaties onder GEGEVEN, testacties onder ALS en resultaten onder DAN, (bekend van de Gherkin schrijfwijze) heb je meteen alles op een rij. Het volledige (logische) testgeval staat voor je neus en extra administratieve inspanning om er logische testgevallen van te maken is niet nodig.

Scenario’s
Je kunt ook tests aan elkaar rijgen: als het resultaat van bepaalde tests gelijk is aan de start van een andere tests, ontstaan scenario’s.
Zo zie je dat een paar gereedschappen die je al kent sinds je eerste testcursus of testboek nog steeds goed van pas komen! Back to the roots dus.

NieuwsMagazine
Ik gebruik de classification tree ook vaak maar de tip om in te delen in GEGEVEN, ALS en DAN, waarmee je in feite de logische testgevallen hebt, vind ik fantastisch.
thx!
Je hebt helemaal gelijk! Men vergeet met de stap naar automation of in Agile projecten ook wel eens dat de basis ligt bij het bedenken van goede testgevallen. Hiervoor kun je heel goed “Back to the roots”.