
Auteur: Erik Skoda ● E.Skoda@chello.nl
Redactie: Eric Spaargaren

Het begrip Kunstmatige Intelligentie geniet de laatste jaren toenemende aandacht in diverse media, maar het bestaat al vele decennia. Het artikel “On computable numbers, with an application to the entscheidungsproblem” van Alan Turing, gepubliceerd in 1936 geldt als een mijlpaal. Wanneer we op internet zoeken naar een definitie vinden we vooral lange uiteenzettingen maar geen eenduidige korte definitie. Het begrip intelligentie zelf is ook op vele manieren gedefinieerd met betrekking tot de onderwerpen; variërend van logica en begripsvorming tot zelfbewustzijn, emotionele kennis en probleemoplossend vermogen.
Machine Learning geldt als een deelverzameling van Kunstmatige Intelligentie. Kenmerkend zijn het verwerken van grote hoeveelheden diverse data, al dan niet onder menselijke supervisie. Deep Learning geldt als een veel bredere, diepere en ambitieuzere implementatie van Kunstmatige Intelligentie.
Als mens zijn we onder andere sterk op gebieden als creativiteit en alertheid-op-snelle-bewegingen. Minutieus miljoenen pixels vergelijken is geen vaardigheid die we de afgelopen tienduizenden jaren nodig hebben gehad om te overleven. Daar ligt onze kracht niet. Een machine is wel in staat om snel en perfect optische verschillen te waarnemen en zodoende al dan niet relevante tekortkomingen te detecteren.
Met het bouwen van automatische testtooling voor automatisering van web applicaties heb ik ruime ervaring. Mijn inzichten zijn daarop gebaseerd. In dit artikel geef ik mijn visie weer, geen absolute waarheid, om hier helder in te zijn. Een ICT-er met andere ervaring komt mogelijk tot andere inzichten.
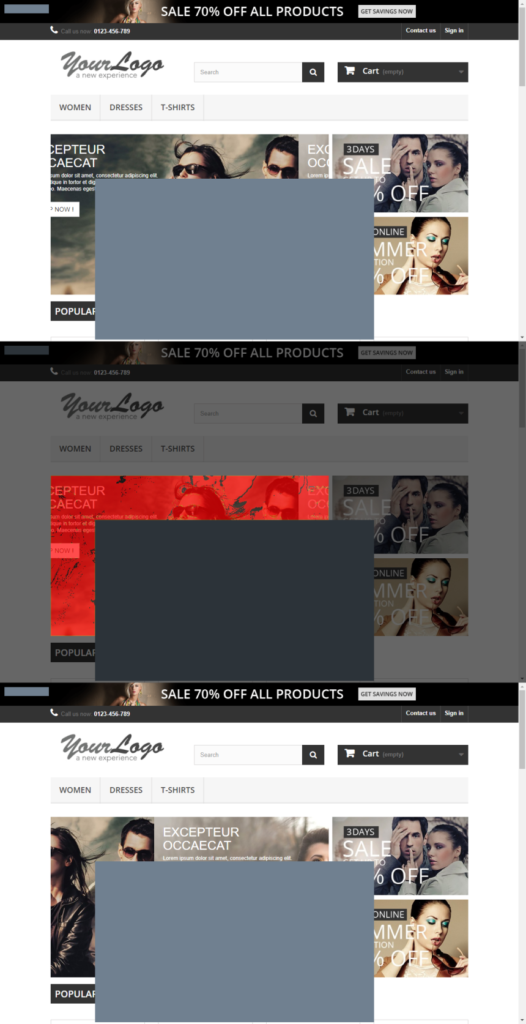
Deze afbeelding toont een referentie screenshot met het verwachte resultaat (boven) het actuele screenshot (onder) en de gevonden verschillen (midden). De gevonden verschillen zijn rood gemarkeerd. De grijze rechthoek is een filter om dynamische content uit te sluiten van de vergelijking, in dit voorbeeld is het filter 100 pixels naar rechts en naar onder verschoven om een verschil te forceren. De screenshots zijn genomen van de test website http://automationpractice.com De gebruikte image tooling is “Blink-diff” van Yahoo. De imagetooling is aangeroepen vanuit testtooling geschreven in C#.
Oplossingsrichting
Voor de toepassing van Kunstmatige Intelligentie in testautomatisering zie ik een aantal potentiële oplossingsrichtingen. Mijns inziens is een enkele daarvan op korte termijn praktisch haalbaar, toepasbaar en financieel verantwoord in testautomatisering.
Toepassingen die ik in beeld heb zijn:
- Detectie van optische verschillen in de scherm presentatie van een applicatie t.o.v. een eerdere versie.
- Verhoging van de stabiliteit van een geautomatiseerd script.
- Een toepassing die door een applicatie navigeert en verschillen detecteert.
- Hulpmiddel voor identificatie van menu items, knoppen, invoervelden, checkboxen, etc.
In dit artikel kijken we naar toepassing 1. Voor mijn gevoel levert dit het beste rendement en het snelste resultaat op. Cruciaal voor succes is het onderkennen van beperkingen van de techniek en het vinden van oplossingen.
Optische verschillen in schermafbeeldingen kunnen een indicatie zijn voor een defect. Het gaat hier om een visuele regressietest. Er is geen algoritme dat vooraf bepaalt welk pixel welke kleur moet hebben, het systeem “leert” dit door bij de eerste uitvoering referentiescreenshots te maken en op te slaan. Een screenshot kan miljoenen pixels bevatten en om deze door een mens laten vergelijken is geestdodend en financieel niet betaalbaar. Een machine is veel beter in staat om dergelijk monotoon en arbeidsintensief werk uit te voeren.
Mijns inziens zijn er op dit moment minimaal drie filters nodig om de techniek volwassen te kunnen toepassen.
1. Een filter voor een knipperende cursor.

Een knipperende cursor kan ten onterechte als een verschil worden gezien. Keuze van beeldverwerkingstechniek welke dit kan filteren is de beste oplossing.
2. Het filteren van anti-aliassing.

Ook beeldverwerking om een mooier en gladder beeld te bereiken – anti-aliassing – kan ten onrechte als verschil worden aangemerkt. Keuze voor beeldverwerkingstechniek die anti-aliassing er uit kan filteren is de meest voor de hand liggende oplossing. Een alternatief heb ik zo snel niet. Zelf tooling ontwikkelen die afbeeldingen vergelijkt gaat nu te ver. Bedrijven als Google, Uber, Yahoo en Yandex als ook kleinere studio’s hebben hiervoor al tools gemaakt die vaak gratis downloadbaar zijn en die vanuit een framework aanroepbaar zijn.
3. Het filteren van dynamische content.
Dynamische content – nieuwsfeeds, weerberichten, beurskoersen, verkeersinformatie, een tijdweergave – kan onterechte defectmeldingen genereren. Het kiezen van beeldverwerkingstechniek die delen van de afbeelding blokkeert is een oplossing. Een alternatief is goed haalbaar.
Welke tooling? Op onderzoek!
Mijn onderzoek naar tooling: de keuze van tooling die je vanuit een test framework aanroept is bepalend voor het resultaat. De tooling met de meeste downloads is compact, eenvoudig te configureren, snel aan de praat te krijgen maar bevatte géén van de drie filters. Diverse andere tools bevatten twee van de drie filters. Sommige worden niet meer onderhouden – zolang bestandsformaten niet wijzigen en de “image diffing” stabiel is maakt dat niet zo heel veel uit, een enkele heeft documentatie in het Russisch wat ik niet beheers. Een stabiel werkende tool met twee van de drie filters waarbij een derde zich op een andere manier laat realiseren is goed genoeg voor een volwassen visuele regressie test.
Let wel, er zijn onterechte verschillen die geen enkele tooling er uit zal kunnen filteren. Wanneer er vlak voor de feestdagen een boodschap in beeld verschijnt om klanten prettige dagen te wensen, zal een menselijke operator direct de link leggen dat het hier wellicht om een boodschap van de marketing afdeling gaat – en dit verifiëren. Tooling ziet slechts 200.000 pixels verschil.
Goede filters zullen het aantal gevonden niet relevante verschillen sterk reduceren, menselijke supervisie blijft noodzakelijk.
Conclusie
Om de analyse van resultaten te automatiseren ben je er niet met Machine Learning. Dan heb je tooling nodig die belt met de marketing afdeling, met een vriendelijke stem vraagt of de collega die de meldingen naar de web applicatie verzorgt aanwezig is, het gesprek aangaat om te bepalen of dit de juiste boodschap is en misschien ook of deze boodschap al op de huidige datum actief moet zijn. We begeven ons dan al heel snel op het terrein van Deep Learning en bij voorkeur beschikken we dan ook over een Turing machine.
Dit is Science fiction op dit moment. Dit geldt ook voor automatisering van betere graafwerk zoals Failure Mode Effect Analysis en Exploratory Testing. Ook zaken als het vormen van een beeld van omgeving, architectuur, deadlines en business risico’s zijn vooralsnog niet met kunstmatige intelligentie uit te voeren.
Een gerichte toepassing van Machine Learning voor een beperkte toepassing, te weten het vergelijken van screenshots vanuit een framework, met als doel een volwassen en haalbare visuele regressietest – dus geen proof of concept – is naar mijn verwachting op zeer korte termijn realiteit.
En voor Turing machines en deep learning geef ik geen prognose af.
Ik ben benieuwd of je Sikulix ook beoordeeld hebt in je onderzoek?
Heb je al eens gekeken naar https://orangebeard.io ?